How well have your tests exercised your code?
Over the course of this posting I plan to demonstrate a number of tools and topics that encompass “testing”. I’ll be looking at code coverage – how much of our code is “exercised” or used. I’ll be looking at tools that can help us with code coverage. I’ll focus on using NUnit for testing and will demonstrate how we can tie it into the code coverage activity. Finally, I’ll be looking how we can integrate all of this good stuff into the Visual Studio IDE…using TestDriven.NET.
With that in mind, I will go through the following:
- The creation of a simple class that does something trivial, in this case a calculator (Visual Studio, C#)
- The creation of a simple front-end application that uses the calculator (Visual Studio, C#)
- An examination of code coverage using the front-end application (NCover and NCoverExplorer)
- An examination of code coverage using unit tests (NUnit)
These four topics will demonstrate two things. Firstly, the benefit of using a code coverage tool to help you learn more about your application and the way that it works. Secondly, how that added benefit of a set of unit tests coupled with a code coverage tool can yield increased levels of confidence in your application’s testing strategy. Of course, prior to code coverage tools being automated, the simplest form of code coverage was the debugger: even as recently as 1998 I recall laboriously slaving over the Delphi debugger whilst I was “testing” my application. It was worth the toil, the few additional bugs that came to light meant that the application had years of trouble free use. Now, with code coverage integrated into the IDE, and with unit tests sitting side-by-side with the application source code, the time required to run the tests and perform a code coverage analysis is so short, it can be done with every build.
TestDriven.NET
TestDriven.NET provides an integration layer between a number of testing frameworks, such as NUnit, and the IDE. Before TestDriven.NET, we would write our tests, write some code, build everything and then we would fire up a separate application that would run the tests (e.g. the NUnit front-end). Generally this is/was fine as the benefits of test execution greatly outweighed the use of a secondary application. Whilst the NUnit front-end allows us to choose which tests we want to run (as opposed to running all tests), we still find ourselves leaving the IDE and jumping into another application.
So, in addition to integrating NUnit into the Visual Studio IDE, it also provides integration with NCover and NCoverExplorer.
Code Coverage
For the purposes of this posting, I am going to do and explain things in a slightly “out of order” fashion. I know that I have mentioned test-driven development already, and by rights we should be developing our application in that fashion. However, I would like to introduce code coverage first. Luckily the example that I plan to use is so simple, it could almost be tested without the need for test-driven development. The example that I plan to use to demonstrate code coverage is that of a simple calculator – I could have been more original, I apologise for my banality!
The Calculator Class
Implementing a simple calculator isn’t rocket science, but since I need you to be at least familiar with the code layout, here’s the code that I am using:

Here’s a little front-end WinForms application that makes use of [some] the MyCalculator class.

And here’s the code behind the WinForms application and the “add” button:

So, having compiled CalcApp, we can submit the .exe to NCover. Before we do that, it’s probably useful if I introduce NCover.
What is NCover?
NCover is a command-line tool that scans your application’s code and records information about which lines of code were executed. NCover uses the “sequence points” that the compiler generates and stores in the .pdb file (debug information) to determine which lines of code are executed and how frequently. Without getting bogged down in detail, a sequence point is essentially a single program state or a line of code.
NCover’s command-line syntax is:
Usage: NCover /c [/a ]
/c Command line to launch profiled application.
/a List of assemblies to profile. i.e. "MyAssembly1;MyAssembly2"
/v Enable verbose logging (show instrumented code)
After NCover has analysed your code, it creates two files: coverage.log and coverage.xml.. The .log file contains the events and messages that NCover creates as it analyses your code base. The .xml file is very it all happens: it contains NCover’s analysis of your code base. There is a third file, coverage.xsl. It’s an XSL stylesheet that takes coverage.xml as its input, allowing it to be displayed in a neat tabular fashion inside Internet Explorer.
Running CalcApp through NCover
NCover’s output:
C:\Program Files\NCover>NCOVER.CONSOLE "...\dev\VS2005\Test\DDG\CalcApp\CalcApp\bin\Debug\CalcApp.exe"
NCover.Console v1.5.4 - Code Coverage Analysis for .NET - http://ncover.org
Copyright (c) 2004-2005 Peter Waldschmidt
Command: ...\dev\VS2005\Test\DDG\Calc
App\CalcApp\bin\Debug\CalcApp.exe
Command Args:
Working Directory:
Assemblies:
Coverage Xml: Coverage.Xml
Coverage Log: Coverage.Log
Waiting for profiled application to connect...
******************* Program Output *******************
***************** End Program Output *****************
Alternatively, with TestDriven.NET installed, there is the IDE menu integration:

It’s important to note that the Coverage menu option is context sensitive. Depending upon “where” you right click, say either on the CalcApp solution or the TestLibrary, NCover will be invoked for the item you right clicked on. We will see this difference emerge later on in this posting when we demonstrate the difference between code coverage for CalcApp vs. code coverage for our NUnit tests.
Now, you may recall that I only implemented the “add” calculation. This is deliberate as I need to use the missing calculations to demonstrate code coverage.
Coverage.xml is too large to reprint here and it’s not all that easy to read. Fortunately, NCover’s author realised this and created an XSL (stylesheet) that transforms the XML into something a) more readable and b) more useful. The screenshot below presents a snapshot of that output – notice the green bars and red bars, we’re clearly in the ‘testing’ domain now. The full NCover coverage.xml file can be viewed here.
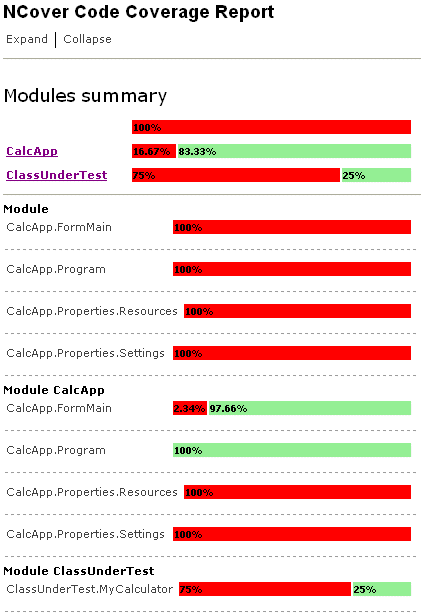
From this report, we can easily see that we’ve only covered 25% of the MyCalculator class. However, and this is a key point, in order to get this far, we had to perform manual testing. We had run the application “through NCover” such that it could watch what was happening. We had to enter the number 38 and 4 and we had to move the mouse and click on the Add button. Whilst this is a better than stepping though code with the debugger, it’s not automated therefore it’s not repeatable.
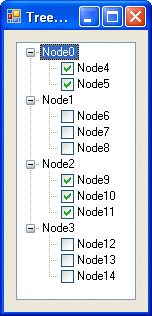
NCover’s report looks great and it serves a good purpose. NCoverExplorer moves things to the next level, it takes the output from NCover and presents it graphically in a treeview with integrated code viewing:

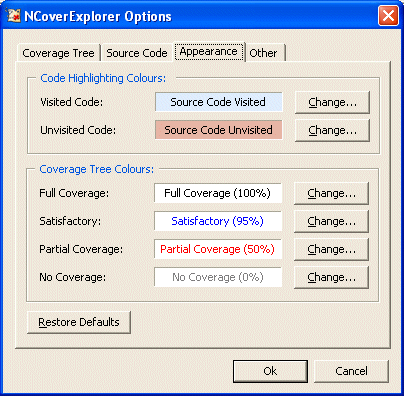
NCoverExplorer uses colour-coding to highlight the status of code coverage. It is configurable as the screenshot below demonstrates:
Introducing unit tests with NUnit
Without going into too much detail about test-driven development and NUnit (further information can be found in the Resources section of this post), our next step is to prepare a new class that allows us to test the MyCalculator class. In reality, we would have written our tests before writing the MyCalculator class, we’re doing things in a slightly different order for the sake of this post.
So, using Visual Studio we simply add a new Class Library to our solution, add a reference to the ClassUnderTest namespace and we’re off. The following code demonstrates how we might use the NUnit testing framework to exercise MyCalculator. Whilst not an NUnit requirement, I prefer to name my test methods with the prefix “test”, other unit testing frameworks may vary. As you can see, we’re simply recreating the manual test that we performed using the desktop application and we’re still only testing the “add” method.

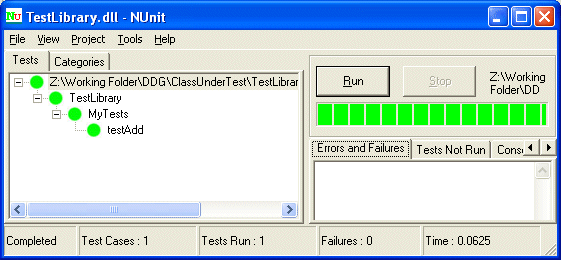
Inviting NUnit to run these tests, in the absence of TestDriven.NET, would mean leaving the IDE. However, with TestDriven.NET, we can right click on the TestLibrary and run the tests using NUnit. The screenshot below presents the output from the NUnit front-end. It clearly demonstrates that the test for addition succeeded and with that we gain the confidence that “everything’s working”. However, what it doesn’t tell us is the fact that we’ve missed out testing some 75% of the MyCalculator class. For that, we need to use NCover on our tests.
Here’s a screenshot of NCoverExplorer viewing NCover’s Coverage.xml after it has analysed the tests:

The key takeaway from this screenshot, and indeed this posting, is the fact that we have automated our test and our code coverage: we can see in a single screenshot how well our tests are exercising our code.
I discovered NCover and NCoverExplorer via a couple of blog posts and was suitably impressed – I am always on the look out for ways of ensuring that my applications are as well tested as they can be. After all, there is nothing worse than a stream of ‘phone calls from your users each complaining about a show stopping crash or feature that does not appear to work. With careful use of the tools mentioned above, we can get ensure that our applications are tested and that we have no code that is unused. Code that is unused is often the source of bugs or feature failures. In the past, without tests and without code coverage tools, we had to resort to using a debugger to test all paths through our code – that was a laborious process fraught with repetition and boredom.
My recommendation: install NCover, install NCoverExplorer, install NUnit, install TestDriven.NET.
Further Reading
TestDriven.NET
TestDriven.NET Google Group
NUnit
MbUnit
Microsoft Team System
Peter Waldschmidt.’s NCover
NCoverExplorer
NCoverExplorer FAQ
DotNet Developers Group articles:
Test-Driven Development: a practical guide, Nov/Dec 2003
Test-Driven Development Using csUnit in C#Builder, Jan/Feb 2004